Note
Click here to download the full example code
Discriminative connection identification¶
What you’ll learn: Build a model around the weight of a linear classifier to identify the discriminant connections.
Author: Dhaif BEKHA
Retrieve the example dataset¶
In this example, we will work directly on a pre-computed dictionary, that contain two set of connectivity matrices, from two different groups. The first group, called controls is a set of connectivity matrices from healthy seven years old children, and the second group called patients, is a set of connectivity matrices from seven years old children who have suffered a stroke. You can download the dictionary use in this example here. Finally, we will plot some results on a glass brain, and we will need the nodes coordinates of the atlas regions in which the signals were extracted. You can download the atlas, and the corresponding labels. As usual, we will suppose that all needed files are in your home directory.
Modules import¶
from pathlib import Path
import os
from conpagnon.utils.folders_and_files_management import load_object
from conpagnon.machine_learning.features_indentification import discriminative_brain_connection_identification, \
find_top_features
import numpy as np
from conpagnon.data_handling import atlas
from conpagnon.utils.array_operation import array_rebuilder
from nilearn.connectome import sym_matrix_to_vec
from sklearn.model_selection import cross_val_score, StratifiedShuffleSplit
from sklearn.svm import LinearSVC
import matplotlib.pyplot as plt
import pandas as pd
Load data¶
We load the subjects connectivity matrices dictionary, and the atlas that you previously downloaded.
# Fetch the path of the home directory
home_directory = str(Path.home())
# Filename of the atlas file.
atlas_file_name = 'atlas.nii'
# Full path to atlas labels file
atlas_label_file = os.path.join(home_directory, 'atlas_labels.csv')
# Set the colors of the twelves network in the atlas
colors = ['navy', 'sienna', 'orange', 'orchid', 'indianred', 'olive',
'goldenrod', 'turquoise', 'darkslategray', 'limegreen', 'black',
'lightpink']
# Number of regions in each of the network
networks = [2, 10, 2, 6, 10, 2, 8, 6, 8, 8, 6, 4]
# We can call fetch_atlas to retrieve useful information about the atlas
atlas_nodes, labels_regions, labels_colors, n_nodes = atlas.fetch_atlas(
atlas_folder=home_directory,
atlas_name=atlas_file_name,
network_regions_number=networks,
colors_labels=colors,
labels=atlas_label_file,
normalize_colors=True)
# We now fetch the subjects connectivity dictionary
# Load the dictionary containing the connectivity matrices
subjects_connectivity_matrices = load_object(
full_path_to_object=os.path.join(home_directory, 'raw_subjects_connectivity_matrices.pkl'))
# Groups names in the dictionary
groups = list(subjects_connectivity_matrices.keys())
Understand and analyze the results of a classifier¶
In the basic section, we saw an example of two groups classification using a classifier, a **S**upport **V**ector **M**achine (SVM) with a linear kernel. Please, do not hesitate to go back to the two groups classification tutorial if needed. Briefly, with a SVM we perform a classification task between patients and controls, with a Stratified and Shuffle cross-validation scheme. This task is performed for the correlation, partial correlation and tangent space connectivity matrices. We compute and store the accuracy for each of those connectivity metric.
# Labels vectors: 0 for the first class, 1 for the second. Those
# 1, and 0 are the label for each subjects.
class_labels = np.hstack((np.zeros(len(subjects_connectivity_matrices[groups[0]].keys())),
np.ones(len(subjects_connectivity_matrices[groups[1]].keys()))))
# total number of subject
n_subjects = len(class_labels)
# Stratified Shuffle and Split cross validation:
# we initialize the cross validation object
# and set the split to 10000.
cv = StratifiedShuffleSplit(n_splits=10000,
random_state=0)
# Instance initialization of SVM classifier with a linear kernel
svc = LinearSVC()
# Compare the classification accuracy across multiple metric
metrics = ['tangent', 'correlation', 'partial correlation']
mean_scores = []
# To decrease the computation time you
# can distribute the computation on
# multiple core, here, 4.
n_jobs = 4
# Final mean accuracy scores will be stored in a dictionary
mean_score_dict = {}
for metric in metrics:
# We take the lower triangle of each matrices, and vectorize it to
# produce a classical machine learning data array of shape (n_subjects, n_features)
features = sym_matrix_to_vec(np.array([subjects_connectivity_matrices[group][subject][metric]
for group in groups
for subject in subjects_connectivity_matrices[group].keys()],
), discard_diagonal=True)
print('Evaluate classification performance on {} with '
'{} observations and {} features...'.format(metric, n_subjects, features.shape[1]))
# We call cross_val_score, a convenient scikit-learn
# wrapper that will perform the classification task
# with the desired cross-validation scheme.
cv_scores = cross_val_score(estimator=svc, X=features,
y=class_labels, cv=cv,
scoring='accuracy', n_jobs=n_jobs)
# We compute the mean cross-validation score
# over all the splits
mean_scores.append(cv_scores.mean())
# We store the mean accuracy score
# in a dictionary.
mean_score_dict[metric] = cv_scores.mean()
print('Done for {}'.format(metric))
# Lets print out the accuracy for each metric
for metric in metrics:
print('{} accuracy: {} %'.format(metric, mean_score_dict[metric] * 100))
Out:
Evaluate classification performance on tangent with 53 observations and 2556 features...
Done for tangent
Evaluate classification performance on correlation with 53 observations and 2556 features...
Done for correlation
Evaluate classification performance on partial correlation with 53 observations and 2556 features...
Done for partial correlation
tangent accuracy: 89.69000000000001 %
correlation accuracy: 82.03833333333334 %
partial correlation accuracy: 87.58666666666667 %
We input a set of 2556 features, i.e, the connectivity coefficients,
to the classifier. In the training phase, the classifier give a
weight to each input features. It’s very common that
the features have not the same importance in the decision
whether for a given subject it’s a patient or a control
subject. If we simplify, some feature are “not so important”
in the final decision, and they have a “small weight” compared
to some other feature that are more important in the final
decision, with higher weight. The idea of the algorithm
that we detailed below is explore the classifier weight
and build a statistic for those weight to find the
more important one.
Important
We will use the tangent space metric only for the rest of this tutorial. The tangent space metric is better suited for classification task, and in general, to pinpoint individual difference in functional connectivity. We detailed why in another tutorial of the advanced examples. Do not hesitate to dive deeper in the subject if you need to.
Discriminative connection identification: the algorithm¶
The presented algorithm was created by Bertrand Ng & al, and we encourage you to read the full paper with a deeper dive in the theory here. Let’s consider we have \({ d\Sigma^{1} ... d\Sigma^{S} }\), the tangent matrices of the whole cohort (patients and controls), with the corresponding labels vector \([0, 0, ..., 1, 1 ,1]\), coding \(0\) for a control subject, and \(1\) for a patient. We first compute the classification for this set of tangent matrices and labels, which results in a vector of weights, \(\omega\). We then, randomly permute \(N\) times the labels vector. Then, for each permutation, we perform the classifier learning on a bootstrapped sample of size \(B\). So, for each permutation, for each bootstrapped sample we compute the classifier weights \(\omega_{n, b}\) with \(b \in {1, ... B}\) and \(n \in {1, ... N}\). For each permutation we ended up with a matrix weight of size \((B, n_{features})\). We then compute the normalized weight over the bootstrapped sample:
We then, store the maximum normalized weight for the permutation \(n\). This is the null distribution of maximum normalized weight mean. After the \(N\) permutation we compute \(\Omega_{0} = \frac{1}{B} \frac{\sum_{b=1}^{B}\omega_{b}}{std(\omega_{b})}\) which is simply the normalized weight without permutations. Giving the We finally declare a weight of \(\Omega_{0}\) significant if they are greater than the 99 th percentile of the null distribution, corresponding to a p-value threshold of 0.01. We use the same classifier as the classification task above, that is, a SVM with a linear kernel. We keep the regularization term C to the default value one.
Note
For the negative weights, we store the minimum of the normalized weight mean instead of the maximum. In the end, you will end up with a set of significant negative weight, and a set of positive one. This way of assessing significance is often called maxT (or minT)
We build a function that conveniently wrap all the
detailed step above,
conpagnon.machine_learning.features_indentification.discriminative_brain_connection_identification().
This function parallelize the computation of the bootstrapped weights. In this function, you can also
choose a parametric correction like FDR for example. I encourage you to look up to the docstring before
using it. We write all the useful results in a report, including the top weight labels.
# Stacked the 2D array of connectivity matrices for each subjects
class_names = groups
metric = 'tangent'
# Vectorize the connectivity matrices
vectorized_connectivity_matrices = sym_matrix_to_vec(
np.array([subjects_connectivity_matrices[class_name][s][metric] for class_name
in class_names for s in subjects_connectivity_matrices[class_name].keys()]),
discard_diagonal=True)
# Stacked connectivity matrices
stacked_connectivity_matrices = np.array([subjects_connectivity_matrices[class_name][s][metric]
for class_name in class_names
for s in subjects_connectivity_matrices[class_name].keys()])
# Compute mean connectivity matrices for each class
# for plotting purpose only
first_class_mean_matrix = np.array([subjects_connectivity_matrices[class_names[0]][s][metric] for s in
subjects_connectivity_matrices[class_names[0]].keys()]).mean(axis=0)
second_class_mean_matrix = np.array([subjects_connectivity_matrices[class_names[1]][s][metric] for s in
subjects_connectivity_matrices[class_names[1]].keys()]).mean(axis=0)
# Directory where you wan to save the report
save_directory = home_directory
# Labels vectors
class_labels = np.hstack((1*np.ones(len(subjects_connectivity_matrices[class_names[0]].keys())),
-1*np.ones(len(subjects_connectivity_matrices[class_names[1]].keys()))))
classifier_weights, weight_null_distribution, p_values_corrected = \
discriminative_brain_connection_identification(
vectorized_connectivity_matrices=vectorized_connectivity_matrices,
class_labels=class_labels,
class_names=class_names,
save_directory=save_directory,
n_permutations=100,
bootstrap_number=200,
features_labels=labels_regions,
features_colors=labels_colors,
n_nodes=n_nodes,
atlas_nodes=atlas_nodes,
first_class_mean_matrix=first_class_mean_matrix,
second_class_mean_matrix=second_class_mean_matrix,
n_cpus_bootstrap=8,
top_features_number=10,
write_report=True,
correction='fdr_bh',
C=1)
Out:
Check Bootstrapped class labels for each permutation...
Verifying that bootstrapped sample labels classes contain two labels....
Done checking bootstrapped class labels for each permutation.
Performing classification on 200 bootstrap sample...
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.7s finished
Performing permutation number 0 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 1 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 2 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 3 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 4 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 5 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 6 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 7 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 8 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 9 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 10 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 11 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 12 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 13 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 14 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 15 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 16 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 17 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 18 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 19 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 20 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 21 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 22 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 23 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 24 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 25 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 26 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 27 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 28 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 29 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 30 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 31 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 32 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 33 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 34 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.8s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 35 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 36 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 37 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 38 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 39 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 40 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.8s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 41 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 42 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 43 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.9s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 3.0s finished
Performing permutation number 44 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.9s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.8s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 45 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 46 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 47 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 48 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 49 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 50 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 51 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 52 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 53 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 54 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 55 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 56 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 57 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 58 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 59 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 60 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 61 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 62 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 63 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 64 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 65 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 66 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 67 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 68 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.8s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 69 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 70 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 71 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 72 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 73 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 74 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 75 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 76 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 77 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.6s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 78 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 79 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 80 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 81 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 82 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 83 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 84 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 85 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 86 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 87 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 88 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.9s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 89 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 90 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 91 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.9s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.9s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 3.0s finished
Performing permutation number 92 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 93 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 94 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 95 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.9s finished
Performing permutation number 96 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 97 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 98 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 185 out of 200 | elapsed: 2.7s remaining: 0.2s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Performing permutation number 99 out of 100
[Parallel(n_jobs=8)]: Using backend MultiprocessingBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 52 tasks | elapsed: 0.8s
[Parallel(n_jobs=8)]: Done 200 out of 200 | elapsed: 2.8s finished
Elapsed time for 100 permutations: 5.099279391765594 min
/home/dhaif/anaconda3/envs/conpagnon/lib/python3.7/site-packages/nilearn/plotting/displays.py:1752: FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison
if node_color == 'auto':
Danger
For the sake of computation time, we choose to compute 500 permutation on bootstrapped sample of size 200. We recommend that you runs at least 10,000 permutation on 500 bootstrapped sample size. We also choose a less conservative correction than the original algorithm, a FDR correction dealing with the multiple comparison.
We will not recreate exactly all the plot and information you’ll find in the final report, but in the section below we will first plot the histogram of the top-weight for both positive and negative weights. The full report is stored in your home directory, and contains all the figure, along with a text file with all the analytics you’ll need.
# Find top features
# Rebuild a symmetric array from normalized mean weight vector
normalized_mean_weight_array = array_rebuilder(classifier_weights,
'numeric', diagonal=np.zeros(n_nodes))
normalized_mean_weight_array_top_features, top_weights, top_coefficients_indices, top_weight_labels = \
find_top_features(normalized_mean_weight_array=normalized_mean_weight_array,
labels_regions=labels_regions,
top_features_number=19)
# Convert the array of labels regions into
# a list of string for plotting purpose.
labels_str = []
for i in range(top_weight_labels.shape[0]):
labels_str.append(str(top_weight_labels[i]))
# let's plot the top negative and positive weight
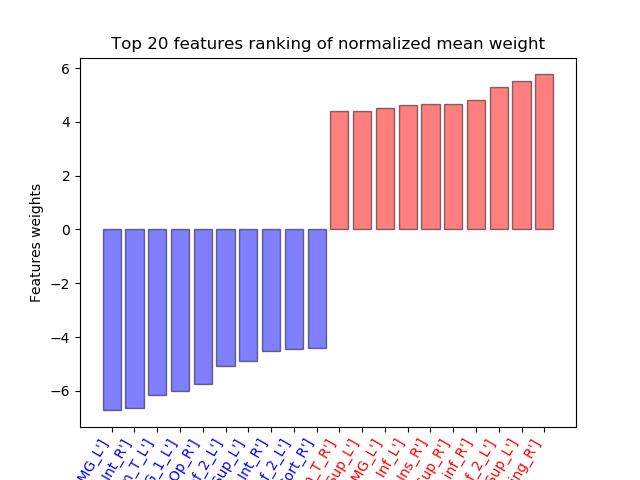
# on a bar plot
weight_colors = ['blue' if weight < 0 else 'red' for weight in top_weights]
plt.bar(np.arange(len(top_weights)), list(top_weights),
color=weight_colors,
edgecolor='black',
alpha=0.5)
plt.xticks(np.arange(0, len(top_weights)), labels_str,
rotation=60,
ha='right')
for label in range(len(plt.gca().get_xticklabels())):
plt.gca().get_xticklabels()[label].set_color(weight_colors[label])
plt.xlabel('Features names')
plt.ylabel('Features weights')
plt.title('Top {} features ranking of normalized mean weight'.format(20))
plt.show()
Out:
/media/dhaif/Samsung_T5/Work/Programs/ConPagnon/examples/04_Advanced_Statistical_Analyses/plot_discriminative_connection_identification.py:331: UserWarning: Matplotlib is currently using agg, which is a non-GUI backend, so cannot show the figure.
plt.show()
Note
The barplot above give you a sense of what will be the import feature, i.e, pairs of regions, that will have a huge impact on the classification decision. For example, it seems that the connectivity between the left and right supra-marginal gyrus and also for the intra-parietal sulcus plays an important role in the classification decision.
Let’s load the text file generated by the analysis. The text file should in your home directory.
# Load the text file:
text_filename = 'features_identification_patients_controls_0.05_fdr_bh.txt'
discriminative_connection_identification_report = pd.read_table(os.path.join(home_directory, text_filename))
print(discriminative_connection_identification_report.to_markdown())
Out:
| | ------------ Parameters ------------ |
|---:|:----------------------------------------------------------------------------------------|
| 0 | Number of subjects: 53 |
| 1 | Groups: ['patients', 'controls'] |
| 2 | Groups labels: [ 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. |
| 3 | 1. 1. 1. 1. 1. 1. 1. 1. 1. -1. -1. -1. -1. -1. -1. -1. -1. -1. |
| 4 | -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1.] |
| 5 | Bootstrap number: 200 |
| 6 | Number of permutations: 100 |
| 7 | Alpha threshold: 0.05 |
| 8 | Regularization parameters C: 1 |
| 9 | ------------ Results ------------ |
| 10 | ------------ Discriminative connections for negative features weight ------------ |
| 11 | Precent_Inf_2_R <-> Precent_Inf_2_L, (indices: 0 <-> 1) |
| 12 | Planum_T_L <-> Planum_T_R, (indices: 2 <-> 3) |
| 13 | Precent_Inf_1_R <-> POS_Sup_R, (indices: 5 <-> 12) |
| 14 | Front_Op_L <-> Front_Op_R, (indices: 22 <-> 29) |
| 15 | SMG_L <-> SMG_R, (indices: 23 <-> 28) |
| 16 | BG_1_L <-> BG_1_R, (indices: 30 <-> 31) |
| 17 | IPS_Int_L <-> IPS_Int_R, (indices: 54 <-> 57) |
| 18 | IPS_Sup_L <-> IPS_Sup_R, (indices: 59 <-> 60) |
| 19 | ------------ Discriminative connections for positive features weight ------------ |
| 20 | Precent_Inf_2_L <-> Precent_Inf_1_L, (indices: 1 <-> 4) |
| 21 | POS_Sup_L <-> Precun_Inf_L, (indices: 13 <-> 36) |
| 22 | CentSulc_Sup_R <-> Cing_Ant_R, (indices: 19 <-> 33) |
| 23 | SMG_L <-> IPS_Sup_L, (indices: 23 <-> 59) |
| 24 | Cun_Sup_R <-> Ling_R, (indices: 40 <-> 53) |
In the text report, you find the full list of the regions that are the most important in the decision, that is, the regions which the p-value associated to the attached weight that are significant. In the pdf report you will find a glass brain plot with the significant positive and negative regions.
Total running time of the script: ( 7 minutes 16.379 seconds)